The Evasion Attack Atlas

A Complete Classification of Adversarial Evasion Techniques
First, a quick recap from Part 1: Intro to AML
In Part 1, we learned that evasion attacks manipulate inputs during inference to fool models. But “evasion attack” is actually an umbrella term covering many different techniques. Think of this post as your treasure map—we’ll explore the entire landscape before diving deep into specific attacks starting from Part 2.
What Exactly is an Evasion Attack?
Before exploring the different families of attacks, let’s clarify what an evasion attack actually is.
Evasion attacks exploit the mathematical foundations of machine learning models by introducing minimal perturbations to inputs. These perturbations push the input across the model’s decision boundary, causing misclassification while remaining semantically equivalent to the original input, meaning a human observer would not notice the change.
In simpler terms:
Small, carefully calculated modifications that fool AI systems but remain invisible to humans..
These attacks specifically target the feature space in which machine learning models operate. Instead of understanding raw inputs directly, models rely on mathematical representations of data to make predictions.
By understanding how models interpret this feature space, attackers can identify weaknesses and craft inputs that exploit the model’s decision boundaries, ultimately forcing incorrect predictions.
The Evasion Attack Tree
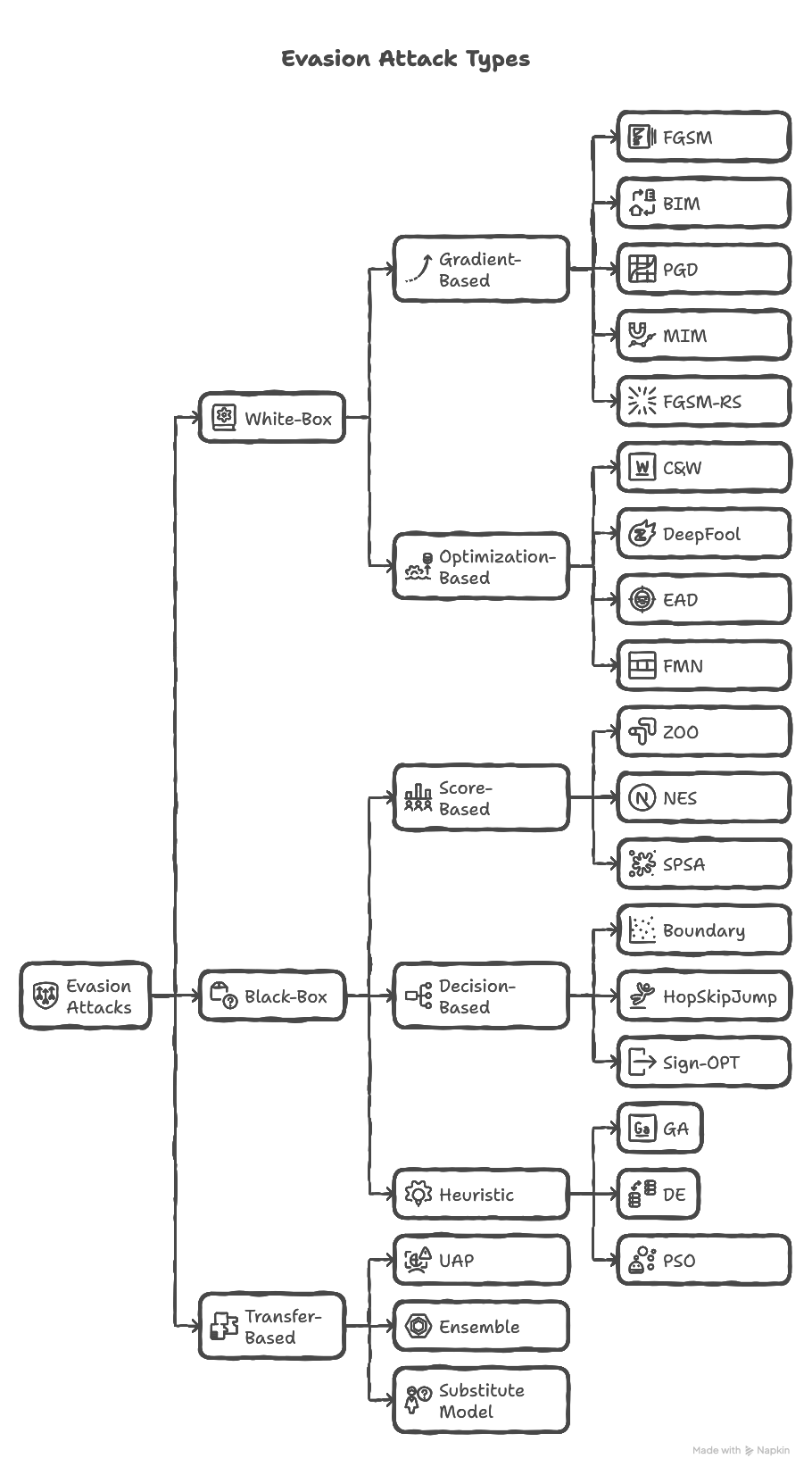
The Six Families of Evasion Attacks
Now that you understand what evasion attacks are, let’s explore the six distinct families, each with its own strengths, weaknesses, and ideal use cases.
Think of this as your attack taxonomy: a map of every major way attackers can fool AI systems.
| Family | Access Level | Key Strength | Best Use Case |
|---|---|---|---|
| Gradient-Based | White-box | Fast & effective | Learning fundamentals |
| Optimization-Based | White-box | Minimal perturbations | Stealth attacks |
| Score-Based | Black-box (soft labels) | No internal access needed | APIs with confidence scores |
| Decision-Based | Black-box (hard labels) | Works with minimal information | Real-world APIs |
| Heuristic / Evolutionary | Any | No gradients required | Discrete / non-differentiable inputs |
| Transfer-Based | Surrogate model | No target access required | Rate-limited APIs |
1. Gradient-Based Attacks
“The Foundation”
| Attack | Full Name | Key Characteristic |
|---|---|---|
| FGSM | Fast Gradient Sign Method | Single-step, uses sign of gradient |
| BIM | Basic Iterative Method | Multi-step FGSM (iterative) |
| PGD | Projected Gradient Descent | BIM + random initialization (strongest) |
| MIM | Momentum Iterative Method | Adds momentum for better transferability |
| FGSM-RS | FGSM with Random Start | FGSM + random initialization |
Threat Model: White-box (requires gradient access)
Core Concept: Use gradients of the loss function with respect to input to craft perturbations. The gradient tells us which direction changes the model’s prediction most dramatically.
Formula Pattern:
\[x_{adv} = x + \epsilon \cdot \text{sign}(\nabla_x L(\theta, x, y))\]When to Use: You have full access to the model (architecture, weights, gradients). This is the fastest family of attacks.
Analogy: Like finding the steepest slope on a hill and taking one big step uphill. The gradient points to where the loss increases fastest.
Why They Matter: These attacks are the foundation of adversarial ML. FGSM (2014) sparked the entire field. If you understand gradient-based attacks, everything else builds on that knowledge.
Coming in Part 2: FGSM deep dive with full math + code!
2. Optimization-Based Attacks
“The Precision Engineers”
| Attack | Full Name | Key Characteristic |
|---|---|---|
| C&W | Carlini & Wagner | Sophisticated optimization, minimal perturbation |
| DeepFool | DeepFool | Finds minimal perturbation to decision boundary |
| EAD | Elastic-Net Attack | Combines L1 + L2 regularization |
| FMN | Fast Minimum-Norm | Faster alternative to C&W |
Threat Model: White-box (requires model access)
Core Concept: Solve a constrained optimization problem to find the smallest possible perturbation that causes misclassification. Unlike gradient attacks that use a fixed ε, these attacks search for the minimal perturbation.
Formula Pattern:
\[\min_{\delta} \|\delta\| \quad \text{subject to} \quad f(x + \delta) \ne y\]When to Use: You need the least detectable perturbations. C&W attacks are famous for breaking defensive distillation (a defense technique).
Analogy: Like a locksmith carefully picking a lock with minimal force, rather than kicking the door down.
Notable Achievement: C&W attacks broke multiple defenses that claimed to be robust. They set a new standard for evaluating defense mechanisms.
3. Score-Based Attacks (Soft-Label Black-Box)
“The Probability Readers”
| Attack | Full Name | Key Characteristic |
|---|---|---|
| ZOO | Zeroth Order Optimization | Coordinate-wise gradient estimation |
| NES | Natural Evolution Strategies | Random search with Gaussian smoothing |
| SPSA | Simultaneous Perturbation Stochastic Approximation | Efficient gradient approximation |
Threat Model: Black-box with confidence scores
Core Concept: Even without knowing the model’s internals, if you can see its confidence scores, you can estimate gradients by probing and observing how scores change.
Access Required: Model returns probability scores (soft labels) for each query.
1
2
3
Query 1: "cat" → [0.87, 0.10, 0.03]
Query 2: "cat" with tiny change → [0.82, 0.15, 0.03]
→ Gradient estimated!
Analogy: Like guessing the shape of an object by tapping it in different places and feeling how it vibrates, you can’t see inside, but you can infer structure from responses.
Query Efficiency: These attacks need many queries (hundreds to thousands) but work on real-world APIs that return confidence scores.
4. Decision-Based Attacks (Hard-Label Black-Box)
“The Blind Navigators”
| Attack | Full Name | Key Characteristic |
|---|---|---|
| Boundary Attack | Boundary Attack | Random walk along decision boundary |
| HopSkipJump | HopSkipJump Attack | Improved boundary attack with gradient estimation |
| Sign-OPT | Sign-based Optimization | Query-efficient sign gradient estimation |
Threat Model: Black-box with only final decision
Core Concept: You get only the final class label no confidence scores. These attacks navigate the decision boundary by probing the model repeatedly and gradually moving along the boundary between classes.
Access Required: Model returns only hard labels. This is the most restricted access scenario.
1
2
3
Example:
Query 1: "cat image with tiny noise" → "cat" (still correct)
Query 2: "cat image with slightly more noise" → "dog" (boundary crossed!)
Analogy: Like being in a dark room and only being told “you’re in the living room” or “you’re in the kitchen.” By moving and checking repeatedly, you can map the walls without ever seeing them.
Modern Advances: Newer attacks like HopSkipJump are surprisingly query-efficient, sometimes finding adversarial examples in just hundreds of queries.
5. Heuristic/Evolutionary Attacks
“The Nature-Inspired Explorers”
| Attack | Full Name | Key Characteristic |
|---|---|---|
| GA Attack | Genetic Algorithm Attack | Selection, crossover, mutation |
| DE Attack | Differential Evolution Attack | Population-based mutation strategy |
| PSO Attack | Particle Swarm Optimization Attack | Swarm intelligence, velocity updates |
Threat Model: Black-box compatible (no gradients needed at all)
Core Concept: These attacks use nature-inspired optimization algorithms to search for adversarial examples.These methods don’t need gradients or even model confidence just a way to evaluate if a candidate is adversarial.
Special Use: Excellent for discrete or non-differentiable perturbations where gradient-based methods fail.
Famous Example: The One-Pixel Attack (changing just one pixel to fool a model) typically uses Differential Evolution (DE).
How GA Works:
1
2
3
4
5
1. Start with population of random perturbations
2. Test which ones fool the model (fitness evaluation)
3. Breed successful ones (crossover)
4. Add random changes (mutation)
5. Repeat until attack succeeds
Analogy: Like evolution finding the perfect adaptation—generate many candidates, keep the ones that work, mutate them, repeat until you find the perfect attack.
Versatility: These attacks work on any model type—neural networks, tree-based models, even non-differentiable systems.
6. Transfer-Based Attacks
“The Copycat Artists”
| Attack | Key Characteristic |
|---|---|
| UAP (Universal Adversarial Perturbations) | Single perturbation fools multiple inputs |
| Substitute Model Attack | Train surrogate, attack it, transfer to target |
| Ensemble Attack | Attack multiple models simultaneously for better transfer |
Threat Model: Black-box via surrogate model
Core Concept: Build your own model (surrogate) that mimics the target, attack your model using white-box methods, and transfer those adversarial examples to the real target.
Why It Works: Different models trained on similar tasks learn similar decision boundaries. An example that fools one model often fools others.
Best For: When you have no direct access to the target model at all (e.g., a proprietary API with rate limiting).
Universal Perturbations: UAPs are particularly scary a single perturbation that can be added to any image to fool the model.
1
2
3
➕ =
[Image] + [Universal Noise] = [Misclassified]
(Any image) (Same noise) (Always wrong)
Analogy: Like practicing against a sparring partner who mimics your real opponent. Once you learn the winning moves, you use the same strategy in the real match.
Why This Taxonomy Matters
Understanding these six families helps us evaluate both attack feasibility and defense strategies.
Different real-world systems expose different levels of access:
- Some expose full models (white-box)
- Some expose probability scores
- Others expose only final predictions
Because of this, adversarial attackers must adapt their strategies depending on what information they can obtain from the target model.
In the next article, we will begin with the simplest and most foundational attack in adversarial machine learning: